一、痛点:同一句话,讲了不知道多少遍
我的工作台是这样的:家里一台 Mac mini,公司一台 MacBook Pro,还有一台云服务器跑一些常驻服务。三台设备上都装着一堆 AI Agent——Claude Code、Codex、OpenClaw、Pi、Kimi、OpenCode,有些用得频繁,有些偶尔需要。
最近时间我在引入 Multica(一个让 Agent 像真实团队成员一样协作的开源平台)。它确实做到了任务分配、进度追踪、技能复用,能把 Claude Code、Codex、OpenClaw 这些 Agent 当成同事来管理——你在 Multica 的看板上建一个 Issue,分配给 Claude Code,它会自主认领、执行、汇报,跟你在 Slack 里协作没什么两样。
Multica 让多个 Agent 协作做一件事变得高效,但它也放大了另一个问题:每个 Agent 的记忆几乎独立——我在 Claude Code 里积累的上下文,OpenClaw 不知道;我在 Mac mini 上调好的偏好,MacBook 上要从头再来。
我的架构偏好、当前项目背景、调试到一半的思路——这些东西,每换一个 Agent、每换一台设备,就归零一次。
二、第一次尝试:Mempalace
调研了一圈,发现 Mempalace 这个项目专门做 Agent 记忆管理。装上之后确实好用——它能把我的偏好、项目背景、历史对话整理成结构化记忆,下次打开 Agent 可以直接召回。
但很快撞上了天花板:单机。
Mempalace 的记忆文件存在本地,Mac mini 上积累的记忆,MacBook 一点都看不到。我研究过把它的 MCP 接口从本地 stdio 转成 HTTP stream 的方案,这样可以把 mempalace 集中在一台服务器上维护,实现远程访问。但不优雅的是需要额外引入一个转换组件来做协议适配——多了一层中间层,不够干净利落。
我需要的是一个原生就跑在云端的记忆中枢。
三、意外发现:OpenHuman 背后的 AgentMemory
有天在 GitHub 刷项目,看到一个叫 OpenHuman 的东西——”你的个人 AI 超级智能”。点进去,发现它的底层记忆后端用的是 AgentMemory。
顺手把 AgentMemory 的 README 从头读到尾。读完眼睛亮了。
这个项目目前在 GitHub 上有 11.6k star,被称为”基于真实 benchmark 排名第一的 AI 编码 Agent 持久记忆系统”。它的核心能力正好命中我的所有需求:
它做到了我一直想要的几件事
支持远程 MCP(HTTP 协议),Agent 在哪台设备都能接入
支持 API Key 认证,只有我的 Agent 才能读我的记忆
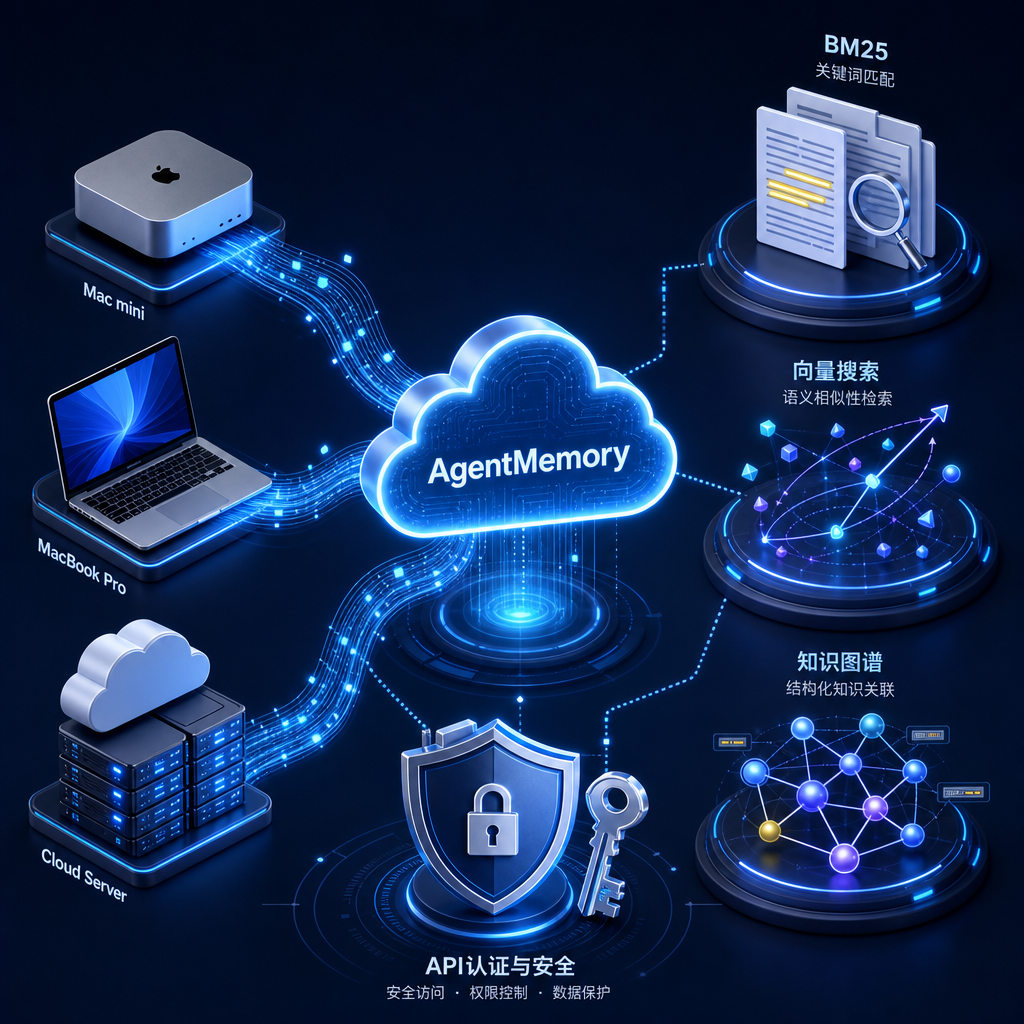
三路混合检索:BM25 关键词 + 向量语义 + 知识图谱,再用 RRF 融合排序
四层记忆整合:工作记忆 → 情节记忆 → 语义记忆 → 程序记忆,像人脑一样分层巩固
兼容几乎所有主流 Agent:Claude Code、Codex、OpenClaw、Pi、Kimi、OpenCode 全支持
不依赖外部数据库,SQLite + iii-engine,自包含部署
更关键的:它原生支持云端部署,提供了 Fly.io、Railway 的一键模板,专门为多设备、多 Agent 的场景设计。这才是我要找的东西。
四、云端部署
选定方案之后,用 OpenClaw 直接部署 AgentMemory 到云服务器。
部署完成后配置 API Key,在各设备的 Agent 里加上 MCP 连接,验证返回 {"status": "healthy"} 即上线成功。
所有设备的所有 Agent,从此共享同一层记忆。
五、现在是什么感觉
接入之后最直接的变化:我在 Mac mini 上用 Claude Code 做了一段工作,讨论了架构决策、确定了代码风格偏好、记录了一个待解决的问题。切换到 MacBook 打开 OpenClaw,它能通过语义检索找到刚才积累的上下文——不需要我重新解释,直接接着上次的思路走。
AgentMemory 能做到语义检索,搜索”agentmemory 远程状态”这类自然语言,能准确召回相关记录,相似度指标显示匹配质量很高——这是纯关键词匹配做不到的。
目前的架构是这样的:
下一步要做的:
- 把偏好文件(USER.md、SOUL.md 里的关键设定)系统性地写入记忆
- 把 Mempalace 单机时代积累的历史数据迁移过来
- 逐步接入剩余的几个 Agent,验证跨 Agent 记忆共享的完整性
六、这件事给我的启发
Agent 协作和 Agent 记忆是两个层次的问题 — Multica 解决的是前者,AgentMemory 解决的是后者。两个工具不冲突,分别在不同维度给 Agent 团队赋能。
个人记忆必须上云 — 本地记忆方案注定是单机的,而我的工作流天然跨设备。”记忆在云上”和”代码在 GitHub 上”一样自然,不该将就。
认证是底线 — 远端记忆服务暴露在公网,API Key 是最低要求。裸奔的记忆系统等于裸奔的云服务器。
语义检索远胜关键词 — 搜”数据库性能问题”能召回”修了一个 N+1 查询”——这不是关键词匹配能做到的。BM25 + 向量 + 图谱融合检索是真实可用的,不只是 README 里的宣传词。
渐进接入,不要一次全上 — 先跑通一个 Agent,确认写入和检索链路完整,再逐步扩展。一次全上出问题找不到根因。
七、我真正想要的
部署 AgentMemory 只是基础设施层面的一步。
我真正想要的是:无论打开哪台设备、无论启动哪个 Agent,它都已经知道我是谁——
我是做平台架构的,习惯先看全局再动手
我喜欢直接型沟通,不需要废话和铺垫
我偏向 Python / Golang、Kubernetes、AI Agent 这个技术方向
我上周讨论过的架构决策,这周要继续往下推
我有一些长期悬而未决的技术问题,不用每次重新解释背景
这些东西,应该像 Git 仓库一样,在任何设备上 pull 一下就有了。
AgentMemory 是实现这个愿景的基础设施。接下来要做的,就是把”我”系统性地写入云端,让每个 Agent 都能读到。
如果你也在用多个 AI Agent,也被跨设备的记忆分裂折磨过,希望这篇文章对你有用。
原文首发于微信公众号「翊行代码」
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2026/05/22/multi-agent-shared-memory/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)