 怎么判断一个 Agent 准不准、靠不靠谱?这大概是过去一年被问得最多、也最没有统一答案的问题。答案不是「跑几个 case 看看顺不顺眼」,而是把「对不对」换成「打没打分、退没退化」——传统单元测试给的是通过或不通过;LLM 流水线的输出是概率性的,模型换一版、prompt 改一行,结果就漂移了,靠精确匹配的断言根本抓不住这种变化。业内把这套新的验收方式叫 Eval-driven Development(EDD):数据集 + 运行器 + 评分器三件套,把打分这件事塞进 CI,跑起来的方式和单元测试没什么两样。 之前那篇 DSPy 实战复盘,是给一个 Skill 写打分函数——管的是一个模块。这一篇要回答的,是把这套判断方法铺开到整条 Agent 流水线上:检索、生成、工具调用、最终输出,每一层都要有能拦下退化的分数线,才谈得上真正知道它靠不靠谱。 —
怎么判断一个 Agent 准不准、靠不靠谱?这大概是过去一年被问得最多、也最没有统一答案的问题。答案不是「跑几个 case 看看顺不顺眼」,而是把「对不对」换成「打没打分、退没退化」——传统单元测试给的是通过或不通过;LLM 流水线的输出是概率性的,模型换一版、prompt 改一行,结果就漂移了,靠精确匹配的断言根本抓不住这种变化。业内把这套新的验收方式叫 Eval-driven Development(EDD):数据集 + 运行器 + 评分器三件套,把打分这件事塞进 CI,跑起来的方式和单元测试没什么两样。 之前那篇 DSPy 实战复盘,是给一个 Skill 写打分函数——管的是一个模块。这一篇要回答的,是把这套判断方法铺开到整条 Agent 流水线上:检索、生成、工具调用、最终输出,每一层都要有能拦下退化的分数线,才谈得上真正知道它靠不靠谱。 —
一句 prompt 改动,怎么在 12 小时内烧穿一条业务线
传统软件是确定性的:同样的输入永远返回同样的输出,所以断言可以是精确匹配(assertEqual)。LLM 不是这样——它不会「崩」,它会悄悄漂移:模型静默更新、prompt 改一行、温度调一档,行为就变了,而你的代码一个字没动。 举个已经被复盘烂了的例子:支持工单的 prompt 里加了一句「始终用温暖、口语化的语气回复」,12 小时后,合法退款请求的拒绝率涨了 14 个点——新语气软化了原本用来触发升级的拒绝话术,同时还悄悄弄坏了另外两条链路,团队当时根本没察觉。 这就是 TDD 和 EDD 的根本差别:TDD 基于精确匹配返回 pass/fail,而 EDD 要在多个质量维度上打分——一个回答可以事实正确但太长,也可以格式漂亮却漏了关键信息,单一的布尔判断根本装不下这种情况。 说白了就是把「对不对」换成「有多好、哪一维退化了」。 —
eval 要坐在开发周期的开头,不是结尾
用一组任务专属的 eval(prompt、上下文、期望输出/参考答案)去指导 LLM 应用的开发:它们指导你的 prompt 工程、模型选型、微调,然后你随时能重跑,快速量出这次改动是进步还是退步——社区喜欢管这套做法叫 TDD for LLM-backed apps。 关键在于时机:eval 应该坐在开发周期的开头,用来塑造决策,而不是坐在末尾只能确认或否决。换句话说,eval 是 LLM 应用的「可执行规格说明书」——在你动 prompt 或换模型之前,先把质量标准定下来。 OpenAI 把这套循环压缩成三个词:Specify → Measure → Improve(先说清楚什么是「好」→ 用真实条件去测 → 从错误里学)。而写 eval 这件事,在升级模型或试新模型的时候尤其关键。
这句话尤其扎心:我们训不了模型,但天天在换模型(Opus → V4 Pro → Flash)。没有 eval,每次换模型都是拿线上用户当小白鼠;有了 eval,换模型只是重跑一次测试。
数据集、运行器、评分器:撑起验收的三块砖
把「怎么测」拆开,几乎所有 eval 框架都会收敛到同样三个组件:
| 组件 | 作用 | 怎么落地 |
| **数据集(Dataset)** | 一组输入 / 期望输出对,代表你的测试用例 | 从线上真实 trace 里捞,别自己拍脑袋编 |
| **运行器(Experiment Runner)** | 拿你的流水线跑整个数据集 | 一个脚本 + 一条 CI 命令 |
| **评分器(Evaluator)** | **用程序打分,而不是精确匹配** | 分层:能用代码就别用模型 |
数据集这块有个很具体的经验值:这种「黄金集(golden set)」通常从 25–50 个用例起步,随着你发现新的失败模式再扩充;内容要覆盖最重要的用例、历史事故里的已知失败模式、以及线上监控发现的边界 case。 所谓 LLM 单元测试,说白了就是针对给定输入评估一条 LLM 输出,判断依据是一组写清楚的标准——比如摘要任务,标准可以是「是否包含足够信息」和「有没有原文里没有的幻觉」。 —
评分器怎么选:能用代码,就别劳烦模型判官
 评分手段可以排成一个「成本 / 灵活度」光谱:代码断言最快,适合不需要理解语义的属性,比如延迟、字数、JSON 合不合法、有没有必需关键词;人工评估是黄金标准但不 scale,适合当冒烟测试,抽几条看看就行;LLM-as-a-judge 最慢但最灵活,用另一个模型来程序化判断这条用例过没过。 能用代码断言解决的,就绝不动用模型判官——便宜、确定、快,还不会自己产生幻觉。
评分手段可以排成一个「成本 / 灵活度」光谱:代码断言最快,适合不需要理解语义的属性,比如延迟、字数、JSON 合不合法、有没有必需关键词;人工评估是黄金标准但不 scale,适合当冒烟测试,抽几条看看就行;LLM-as-a-judge 最慢但最灵活,用另一个模型来程序化判断这条用例过没过。 能用代码断言解决的,就绝不动用模型判官——便宜、确定、快,还不会自己产生幻觉。
LLM-as-a-judge 的坑(这部分决定你的验收可不可信)
模型判官很香,但它自己就是个会翻车的模型,已知的系统性偏差有据可查:
- 位置偏差:成对比较时,再强的判官模型也普遍偏爱排在前面的那个输出。
- 数值打分不可靠:让它做二元判断或 1–5 粗档打分还行,但刻度越细,给的分越随机——有人复现过让判官模型给不同拼写错误严重程度的文本打分,结果就很不靠谱。 有一篇实证研究(An Empirical Study of LLM-as-a-Judge)给了三条能直接用的结论:评价标准(criteria)才是可靠性的关键;非确定性采样反而比确定性解码更能对齐人类偏好;当标准已经写清楚时,让判官做 CoT 推理带来的收益很小。 好消息是:经过正确校准 + 人工验证的 LLM 判官,和人类偏好的一致率能超过 80%,达到「人与人之间」那种一致水平。
落地翻译:判官的 prompt 里,标准要写死、写细、给正反例;分数别设太细的刻度(二元或三档最稳);上线前一定拿一批人工标注过的用例,校一遍判官和你自己判断的一致率——判官本身也要被测。
DSPy 的打分函数,铺满整条流水线是什么样子
之前那篇 DSPy 的核心,是给一个 Skill 声明契约 + 打分函数,把措辞交给编译器。DSPy 里的 metric 说得很干脆:一个给单条预测打分的 Python 函数,返回一个优化器可以去追的数字。优化器的本质就是一个循环——把你的程序跑很多遍,留下得分最高的那版。
# DSPy metric:给单条预测打分,这就是「单点验收」 def metric(example, prediction, trace=None): correct = example.answer.lower() in prediction.answer.lower() grounded = "无依据" not in prediction.rationale # 不许编 return correct and groundedDSPy 官网首页那个例子很能说明打分函数的价值:同一条 RAG 流水线,用 GEPA 优化器对着
semantic_f1这个 metric 编译一遍,F1 就从 0.41 提到 0.63——业务逻辑一行没改,只是给了它一把尺子和一个自动循环。 升维的动作,就是把「给单条预测打分」的这把尺子,扩展成「给整条流水线的每一层打分」:
| 层次 | 单点验收(DSPy 那篇) | 全流程验收(这篇) |
| 对象 | 一个 Skill / 一个模块 | 检索 → 生成 → 工具调用 → 最终输出整条链 |
| 手段 | 一个 metric 函数 | 数据集 + 多个评分器(代码断言 + 判官) |
| 触发 | 编译/优化时 | 每次 commit,跑在 CI 里 |
| 目标 | 让这个模块变好 | 防止**任何一层**悄悄退化 |
这就是「从单点验收到全流程验收」的闭环:DSPy 的打分函数是种子,Eval-driven 是把它铺满整条流水线。 —
Agent 的准确性,得看它怎么走到答案的
单条 LLM 调用看输出对不对就够了,但 Agent 不一样——它会规划、选工具、执行、再根据结果调整下一步,最终答案对,不代表中间过程没问题。 这不是危言耸听。斯坦福 HAI 的《2026 AI Index》里有组很扎心的数据:2025 年 AI Agent 已经能从「答问题」进化到「做任务」,但在结构化基准里,大约还有三分之一的尝试会失败。在专门测电脑操作任务的 OSWorld 基准上,准确率一年内从大约 12% 涨到了约 66%——进步巨大,但按这份报告的口径,离「可靠」还有距离。(补一层时间:到 2025 年底,已有单个前沿框架在该基准上追平乃至反超约 72% 的人类基线,只是这类 SOTA 成绩还代表不了 Agent 的整体可靠性。) 所以判断一个 Agent 准不准,光看最终答案是不够的,一般拆成两种查法:一种是黑盒评测,只看输入和最终输出,简单但查不出问题出在哪一步;另一种是轨迹评测,把 Agent 实际走过的工具调用序列,和预期的正确路径逐步比对——最终答案错了,轨迹评测能直接指出是哪一步的推理出了问题。 工具调用这块也不能简单要求「参数一字不差」。更实际的做法是算参数正确率——比如一个工具要传 5 个参数,对了 4 个就是 80% 的工具正确率,而不是非黑即白的判定。已经有专门的轨迹基准测试,除了看最终答案,还会拆开记录工具选不选得对、参数填不填得对、调用顺序对不对——这几项分开记,才看得出 Agent 到底卡在哪个环节。 LangChain 测过工具调用,有个反直觉的结论:函数调用很容易做到 100% 的 schema 正确率(格式对、字段全),但这并不代表任务真的做对了;而且步骤越多,失败概率越高,规划对 LLM 来说始终是块硬骨头。 这条经验直接能用:给 Agent 写 eval,别只在最后一步设断言。中间每一次工具调用、每一次决策分支,都应该留一条能单独打分的记录——这样它翻车的时候,你才知道是选错了工具,还是传错了参数,还是压根没按对的顺序走。 —
手把手:给一个退款 Agent 写轨迹评测
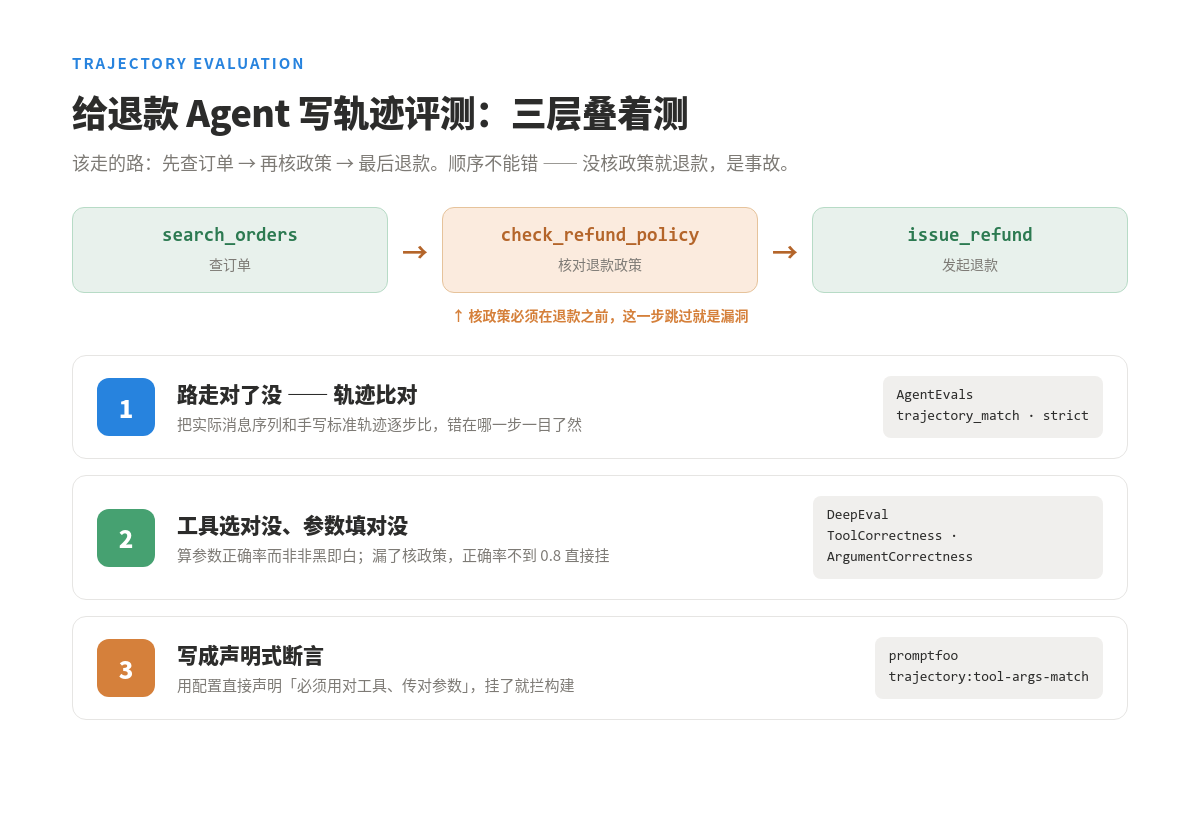 光说不练假把式。拿一个具体的退款 Agent 举例,它该走的路是:先查订单
光说不练假把式。拿一个具体的退款 Agent 举例,它该走的路是:先查订单 search_orders,再核对退款政策 check_refund_policy,最后才发起退款 issue_refund。顺序不能错——没核政策就退款,是事故。下面这三层叠着测,就是把「准不准」落到代码上。 第一层:路走对了没——轨迹比对 LangChain 的 AgentEvals 包里有现成的 create_trajectory_match_evaluator,把 Agent 实际走过的消息序列,和你手写的标准轨迹逐步比:
from agentevals.trajectory.match import create_trajectory_match_evaluator
# strict:顺序必须一致——核政策必须在退款之前
evaluator = create_trajectory_match_evaluator(
trajectory_match_mode="strict",
)
result = evaluator(
outputs=agent_messages, # Agent 实际走过的消息 + 工具调用
reference_outputs=reference, # 你手写的标准轨迹
)
# result["score"] 为 True/False,错在哪一步一目了然
它有四种模式,按业务严格度选:strict(顺序必须一致,适合「核政策必须在退款前」这种硬规矩)、unordered(工具对就行、顺序无所谓)、subset(不许调用参考之外的工具,防越权)、superset(至少调用参考里的工具,允许额外)。 第二层:工具选对没、参数填对没 DeepEval 提供两个专门的 agentic 指标:ToolCorrectnessMetric 看工具选得对不对,ArgumentCorrectnessMetric 看参数生成得对不对:
from deepeval.metrics import ToolCorrectnessMetric
from deepeval.test_case import LLMTestCase, ToolCall, ToolCallParams
test_case = LLMTestCase(
input="我这笔订单被扣了三次,帮我退款",
actual_output="已为你发起退款",
tools_called=[
ToolCall(name="search_orders", input_parameters={"order_id": "123"}),
ToolCall(name="issue_refund", input_parameters={"order_id": "123"}),
],
expected_tools=[
ToolCall(name="search_orders"),
ToolCall(name="check_refund_policy"),
ToolCall(name="issue_refund"),
],
)
# 默认只比工具名;加上 INPUT_PARAMETERS 就连参数一起比
tool_metric = ToolCorrectnessMetric(
evaluation_params=[ToolCallParams.INPUT_PARAMETERS],
threshold=0.8,
)
tool_metric.measure(test_case)
print(tool_metric.score, tool_metric.reason)
这个 case 会挂——因为它漏了 check_refund_policy,工具正确率不到 0.8。而这正是我们想抓的:它嘴上说「已退款」,最终输出看着没毛病,但实际跳过了核政策这一步。两个都是组件级指标,要挂在做工具决策的那个 LLM 节点上。 第三层:把它写成声明式断言 除了在代码里跑指标,promptfoo 还提供了一个专门的 trajectory:tool-args-match 断言,可以用配置直接声明「必须用对工具、传对参数」:
tests:
- vars: { input: "订单 123 被重复扣费,要退款" }
assert:
- type: trajectory:tool-args-match # 查了对的单
value:
name: search_orders
args: { order_id: "123" }
- type: trajectory:tool-args-match # 退款前必须核过政策
value:
name: check_refund_policy
一句话收:判断 Agent 准不准,落到代码上就是这三层叠着测——轨迹对不对(走没走错路)、工具和参数对不对(每一步做没做对)、断言写死(用对工具、传对参数)。哪一层挂了,你立刻知道该去修哪儿。至于怎么让这三层改一次就自动重跑、挂了就拦下构建,下一节专门讲。 —
把 eval 塞进 CI,才配得上「单元测试」这三个字
上面那套退款 Agent 的评测,只有跑在 CI 里、能 fail 掉一次构建,才配叫单元测试;否则它只是个你偶尔想起来才跑一次的脚本。 刚才实战里用到的 promptfoo(开源 CLI + 库,已并入 OpenAI,仍保持 MIT 许可),被社区直接叫做「LLM 应用的单元测试 / 集成测试框架」——声明式配置 + 内置断言 + CI/CD 集成一步到位,除了 Agent 轨迹,普通的输出断言也能一起跑,任何一条不过都会让 CI 任务失败。
# promptfoo:像写单元测试一样声明 eval
prompts:
- "把下面的工单摘要成一句话(工单文本从测试用例注入)"
providers:
- deepseek:deepseek-chat # 换模型只改这一行
tests:
- vars: { input: "用户连续三次被扣费想退款..." }
assert:
- type: contains # 代码断言,最便宜
value: "退款"
- type: latency
threshold: 3000
- type: llm-rubric # 需要语义判断才动用判官
value: "摘要不超过30字,且没有编造原文没有的信息"
# CI 里就一行;任一断言不过,构建直接红
npx promptfoo eval --output results.xml
Python 栈的话,DeepEval 直接接 pytest:加载 goldens → 构造测试用例 → deepeval test run,跑法和你平时跑单元测试一模一样。 这套 CI 化的验收,本质就是回归测试:把新版 prompt 拿去跑标准测试数据集,和当前生产版本的分数对比;只要质量或性能出现回退,CI 就直接 fail 掉构建,跟一个失败的单元测试没两样。一句话总结更狠:prompt 回归测试就是 prompt 版的 pytest。 —
真正跑起来之后,麻烦事都在细节里
把 eval 框架真搭起来跑之后,麻烦都在细节里,拆开看是几件互相咬合的事:先接受 LLM 流水线本身就是非确定的,与其追求 100% 复现,不如上线前就和自己把各维度的及格线定清楚——Agent 会犯错是常态,标准定得太完美只会拖垮上线节奏。数据集尽量从真实 trace 里捞,而不是自己拍脑袋编,25–50 条起步,每出一次线上事故就顺手补一条用例,这份数据集会越滚越结实。评分器该分层就分层:能用代码断言解决的问题不要交给模型判官,判官出场时也只给二元或粗档判断,标准在 prompt 里写死、给足正反例,而且判官本身也要拿一批已知的好坏 case 去测,和人工校准到八成以上一致率再敢信它。剩下的就是工程习惯:建基线、追踪每次改动相对上一版的分数变化,退了就让 CI 直接红;顺手把每次 eval 消耗的 token 和费用记下来,验收本身也是一笔要控的成本。 工具这块不用太纠结,因为工具本来就会变——OpenAI 自己的 Evals 平台就已经宣布退役,存量 eval 将于 2026 年 10 月 31 日转为只读、11 月 30 日关停。真正带得走、和具体工具解耦的,是你的数据集(黄金集)和你写清楚的评价标准;工具换一个,重新接一遍就行,数据集和标准才是留得下来的资产。 之前那篇 DSPy 给一个 Skill 写打分函数,这一篇把同一件事铺满整条流水线、塞进 CI,变成能拦下退化的回归测试——两者其实是同一套心法在不同粒度上的应用。
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2026/07/03/agent-eval-driven/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)