
这篇不绕概念,就一个目标:用大白话把 Harness 讲明白。看完你能一句话告诉别人——它是什么、有什么用、为什么 AI 没它就干不成事。 (写给会用 AI 工具、却时不时被它坑一把的独立创作者和开发者。)
先给结论:Harness 就是「别让 AI 瞎猜」
网上讲 Harness 的文章,十篇有九篇在说「它是套在大模型外面的缰绳 / 脚手架 / 中间层」。比喻都对,但听完你还是不知道它具体管什么。
换个说法,一句到底——Harness 就是把 AI 干活的每一步尽量定死,把「靠它现场发挥」换成「按既定流程执行」。 模型再聪明也只负责「想」;让这份聪明每次都稳稳落地的,才是 Harness。
要更准确一点的定义
抛开比喻:Harness 是位于 Agent 与基础模型之间的「中间层」。它让 AI 不只是「有想法」,而是真正具备能稳定执行的能力。一个常见的拆法是:
Harness = 指令(Instructions) + 工具(Tools) + 环境(Environment) + 反馈(Feedback) + 监控(Observation)
这 5 块不是我随口编的——后面讲 OpenAI 那个实验时,你会看到它们怎么各司其职。
一个生活场景:AI 是厨师长,Harness 是后厨服务团队

想象 AI 是一位厨艺顶尖的厨师长:什么菜都会做,但不能直接碰食材,所有动作都得通过服务团队执行。
| 你想…… | ❌ 没有 Harness | ✅ 有 Harness |
|---|---|---|
| 炒个菜 | 自己冲进厨房瞎折腾 | 服务员递锅 → 你炒 → 服务员装盘上桌 |
| 查菜谱 | 自己爬窗出去找 | 按铃,服务员帮你查好带回来 |
| 改菜单 | 自己拿笔乱涂 | 按铃,服务员调出系统让你选 |
| 后厨安全 | 门开着,谁都能进来捣乱 | 有门禁 + 摄像头,只有授权的人能进 |
一句话:Harness = 那个服务团队——递东西给它、把结果带回来、并确保它只能做该做的事。
代码上更直白
(不写代码也没关系,看注释就懂——重点只在对比「有没有人拦着它」。)
# ❌ 没有 Harness:没人拦得住它
open("secret.txt") # 随便读文件
exec("rm -rf /") # 想删系统?它真会删
# ✅ 有 Harness:只能通过受控接口
harness.tool_call("read_file", path="secret.txt")
# 背后:先查权限 → 隔离环境读取 → 清理敏感信息再返回
AI 根本不知道真实路径在哪,每一次调用都被 Harness 拦下来检查。这就是「能想」和「能安全地干」的区别。
它到底有多猛?看 OpenAI 自己的实验
OpenAI 团队做过一个实验:5 个月、约 100 万行代码、约 1500 个 PR,全部由 Codex 生成,人类工程师一行都没手写,团队最初只有 3 人。1
这怎么做到的?靠的不是一个大模型,而是一整套 Harness:
| 子系统 | 作用 | 具体做法 |
|---|---|---|
| 指令系统 | 告诉 AI 该怎么做 | 用 AGENTS.md 规定项目规范 |
| 工具系统 | 限制 AI 能干什么 | 40+ 工具封装,每样都要走接口 |
| 环境系统 | 防止「本地能跑、CI 就废」 | 锁版本(frozen-lockfile) |
| 反馈系统 | 让 AI 自我纠错 | 生成器写 → 评估器测 → 不过就重写 |
| 监控日志 | 出问题知道在哪 | 记录每一步操作供审计 |
记住这句:不是模型突然变强,而是 Harness 把它管好了。
一张图看懂谁管谁
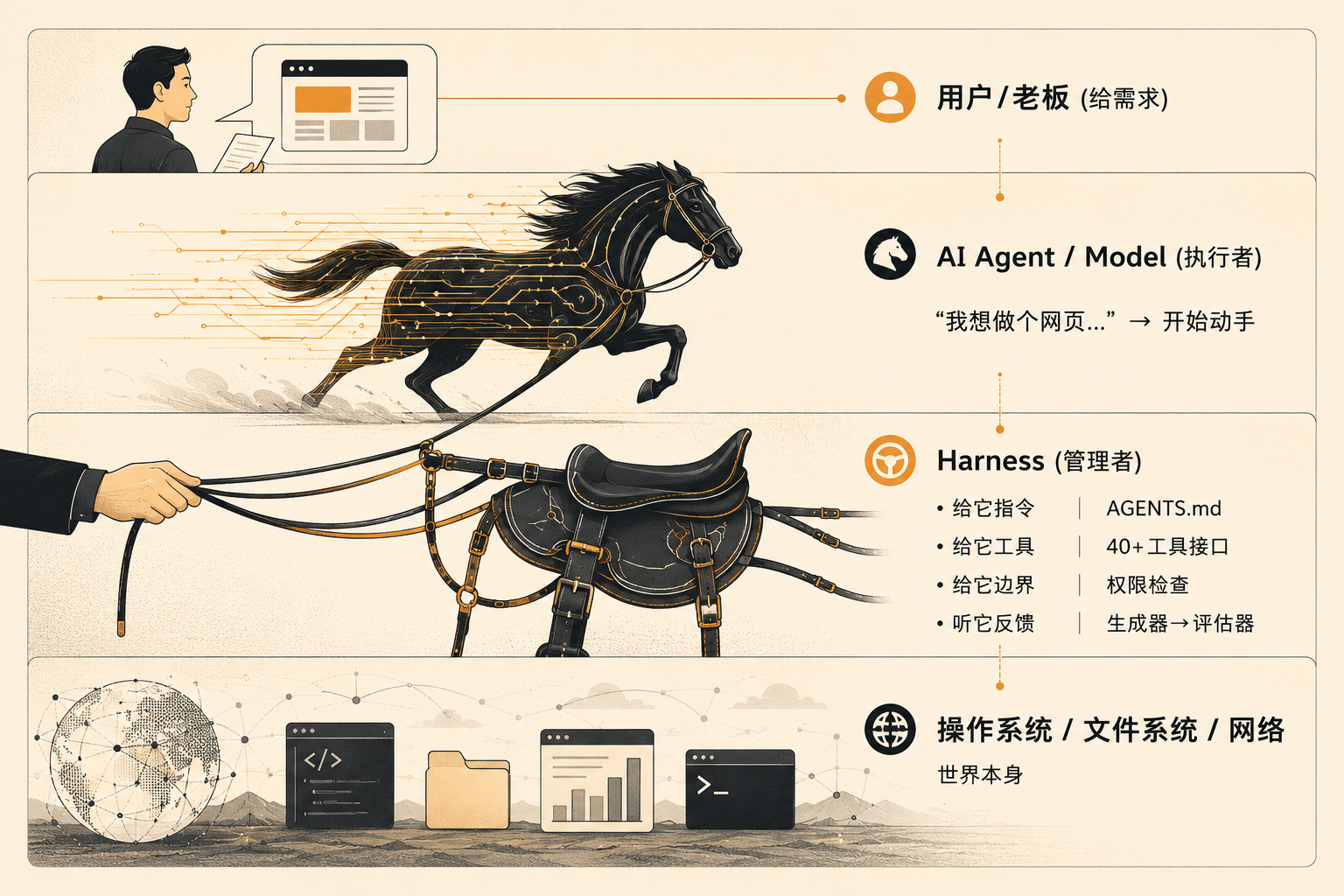
Agent 是马,Harness 是缰绳和马鞍,你是骑手。 没有缰绳,再快的马也只会乱跑;缰绳握在谁手里,谁才说了算。
别搞混:Prompt ≠ Harness
只写一段「你是一个助手,请帮我……」——那只是 Prompt,只决定「说什么」。
Harness 则是「怎么说才能安全有效地把事做成」的一整套:工具接口 + 权限控制 + 反馈机制 + 约束规则。
第一性原理:把每个环节的「变量」摁成「常量」

AI 为什么会跑偏?因为从输入到输出,每个环节都塞满了不确定性——这次要干嘛、它会调什么工具、会不会乱删、格式飘不飘。Harness 的第一性原理只有一句:在每个环节里,尽量减少变量。 把模糊的、随机的东西,逐个变成写死的、可预期的常量。
一个真实的例子:为什么建了 Skill 还老出错
我媳妇每天用 AI 工具处理一个 Excel、自动生成日报,却三天两头出错——有时是大模型自己理解偏了,有时是 Excel 本身格式有问题。她很困惑:明明已经建好了 Skill,为什么还老翻车?
我的回答是:Skill 只告诉了 AI「该做什么」,但每一步具体怎么做,仍然是让大模型现场「推测」——只要有推测,就有变量;有变量,就会出错。
真正的解法是把这条流程「程序化」:读哪一列、怎么求和、遇到异常怎么处理,凡是能写成确定脚本的,就别留给模型临场发挥;模型只做它真正擅长的那部分(比如把算好的数据写成一段通顺的日报)。
一句话:减少大模型的「推测」,就是减少变量。
| 环节 | 变量从哪来(不控就乱) | Harness 怎么把它摁住 |
|---|---|---|
| 输入 | 这次要干嘛、给谁看、什么风格 | 指令 + 动态注入:每次都讲清,不让 AI 猜 |
| 能力 | 它能调什么、会不会乱删 | 工具白名单:只开该开的,高危必须确认 |
| 过程 | 中途会不会跑偏 | 反馈闭环:先提纲 → 确认 → 再写,不过就重来 |
| 环境 | 这次能跑、下次崩 | 锁版本 / 隔离环境:每次环境都一样 |
| 输出 | 格式 / 质量忽好忽坏 | 输出规格 + 验收清单:不达标不算完 |
一句话记牢:变量越少,结果越稳。 你做的每一件 Harness 工作,本质都是在「消掉一个变量」。这也是判断要不要加某个规则/工具的标准——它到底帮你减少了哪个变量?如果答案是「没有」,那就别加。
为什么你平时感觉不到它?
因为你通常接触的是结果,而不是过程。就像用电脑时你不会感知到 CPU 怎么运转,只会觉得「这软件打开挺快」。
所谓「AI 好像变聪明了」,很多时候不是模型变强了,而是背后有人把 Harness 搭好了。
那一个人能怎么用?(简单粗暴版)
你不用马上搭一套复杂系统。先给你的 AI 配齐这「三根缰绳」就够了:
- 指令:写清它是谁、要干嘛、什么不能干(一份固定的 system prompt)。
- 工具:明确它能用哪些工具、哪些动作必须先问你(一张白名单)。
- 反馈:让它先给提纲/草稿 → 你确认 → 再继续,别一把梭。
这三根缰绳具体怎么落地(可直接抄的 system prompt、规则文件、MCP 白名单表),下一篇《一人公司 Harness 指南·中》专门讲。
写在最后
下次 AI 又给你翻车,先别急着骂模型——回头看看:是哪个环节的变量还没摁住?
找到它、把它写死,你就又攥紧了一根缰绳。野马驯成战马,就是这么一根根缰绳攒出来的。
P.S. 哪天你对象又吐槽你部署的 AI 工具不好用——先别急着辩解,把这篇直接转给 ta。
参考
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2026/06/15/harness-explained/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)