一句话:模型正在变成水电,谁都能极低成本用上一流大模型。那么一人公司真正的护城河,不是模型,而是”模型 × 你的结构化上下文 × 编排(Harness)”。
这两周有个问题一直在拉扯我:作为一个人的公司,我的知识系统到底该放哪里——是跟着 Karpathy、跟着半个技术圈搬回本地的 Obsidian,还是继续压在云端的 Notion AI 上?
我亲手踏过两边,最后的结论反而越来越清晰。这篇文章把这个过程和理由完整写下来。
一、缘起:Karpathy 带火的 Obsidian LLM Wiki
先说个背景。Andrej Karpathy 提出了一种叫”LLM Wiki”的玩法:把你的知识以一堆 Markdown 文件的形式沉淀在本地(比如 Obsidian),然后让 AI Agent 直接读这些文件、甚至替你维护它们。本地、纯文本、可版本控制、不被任何平台锁定——听起来像是给 AI 时代的”第二大脑”找到了最优解。
这个题材有多火?我自己的数据可以作证:博客上一篇写 LLM Wiki 的复盘文章连续几周领跑,公众号同题材也是爆款。说明”AI 知识库”这件事,击中了太多人的焦虑。
但热点往往只告诉你”大家在焦虑什么”,不告诉你”正确答案是什么”。我们往下看。
二、新变量:Google OKF 把”本地知识”标准化了
就在最近,Google Cloud 发布了 OKF(Open Knowledge Format,开放知识格式)。它的核心简单到几句话就能说清:一个目录 + 一堆 Markdown 文件 + YAML frontmatter,文件路径就是概念的身份,跨不同 AI Agent 都能读。
很多人把 OKF 误读成”谷歌在号召大家反云、回本地”。恰恰相反。OKF 反的不是云,反的是平台锁定(lock-in)。它要解决的是”我的知识被某个厂商的私有格式绑架”这件事。这里的”本地”,准确说是所有权与可移植性,而不是物理意义上的”跑在我自己机器上”。
这是个好东西。但 OKF 只解决了一件事——可移植性;它没解决协作、没解决结构化、也没解决跨源上下文。于是一个被热点掩盖的问题被逆向逼了出来:如果知识只是一堆可移植的 Markdown,那真正决定体验的到底是什么?
三、三道天花板:本地 LLM Wiki 撞不起一人公司
我把本地 LLM Wiki 当作 Agent 体系的知识底座实验过一段时间,撞到了三道天花板。

1. 协作:单机工具的原罪
Obsidian 本质上是个单用户的桌面应用。多设备同步要买 Sync 或自建方案,多人实时协作更是硬伤。你可能会说”一人公司哪来多人”——但一人公司不是一个人干活,是你指挥一群 Agent 干活。当你有多个 Agent、多个设备、甚至未来还要拉人进来时,单机模型立刻崩。
2. 结构化:纯 Markdown 的表达力上限
这是最被低估的一点。纯 Markdown 文件能写笔记,但表达不了数据库、关联、属性。我的整套工作流是建立在 PARA(项目/领域/资源/归档)和 PDCA 复盘循环上的,这些都需要”状态、关联、滚动统计”这类结构化能力。你可以用 YAML frontmatter 硬塞,但那只是把数据库手工模拟了一遍,连一个 Notion 最基础的看板视图都换不来。
3. 上下文:本地 RAG 是个孤岛
本地知识库的 AI,能检索的只有你本地 vault 里的东西。但我真正的上下文是散在各处的:日计划、RSS 追踪库、邮件、GitHub、网页。一个拿不到跨源全貌的 AI,再聪明也只是个孤岛上的聪明人。
四、成本真相:谁在”极低成本用一流模型”
这是最致命的一刀,也是最隐蔽的一刀。
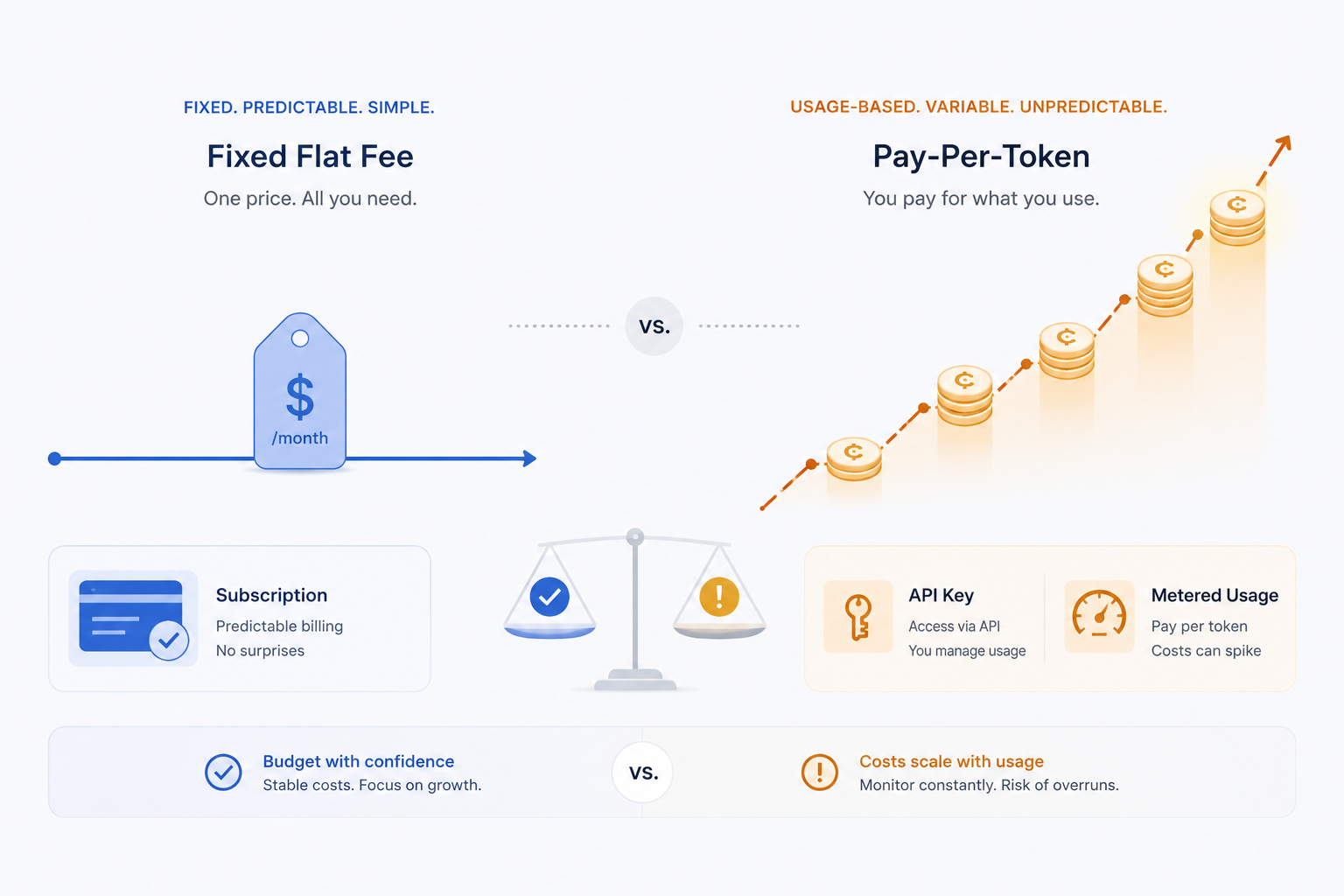
用 Notion AI,你拿到的是被平台摊薄过的固定月费:前沿模型内置、零运维、不用管 API Key 和配额、原生接你整个 workspace 和连接器。
而 Obsidian + LLM 插件的路子,要么是 BYOK(自带 Key)按 token 烧钱、自己管限流和模型切换,要么退而求其次跑本地小模型——质量和速度都打折。
换句话说:”极低成本用上世界一流大模型”这件事,在 Notion 里是平台补贴给你的默认福利;在本地方案里,是你自己往 API 里按量充钱。
诚实的反面:本地方案并非没有牌面。在隐私/合规敏感的数据、需要离线可用、或重度 token 消耗的场景下,自建 BYOK 反而更稳——你能挑模型、挑版本、上微调,数据也不出本机。这些优势是真实的。只是对绝大多数一人公司的日常创作与知识管理来说,它们不是主流场景,却要你为此长期背上运维与成本的包袱。
五、护城河公式:模型 × 上下文 × 编排
把上面几点串起来,会浮出一个更底层的认知:
💡 价值 = 模型 × 你的结构化上下文 × 编排(Harness)
模型本身正在变成水电(commodity)——这是好事,但也意味着它不再是稀缺资源。谁都能便宜买到,它就不可能是护城河。
- Obsidian 路线给你的,顶多是公式里的第一项:原始模型访问。后两项要你自己拿插件一点点拼。
- Notion AI 路线把三项打包了:模型 + 你的数据库/PARA/PDCA 结构 + 跨源理解与自动编排。
这才是重点:当模型变成水电,真正稀缺的是”模型 × 你的私有上下文 × 自动编排”这套 Harness。谁把这三件事的边际成本压到最低,谁就赢。
六、我的选择:把 Notion AI 立为知识底座
所以我最后的做法,其实是复用了自己早就验证过的一个判断:知识、任务、Agent 配置、产出全部走 Notion;本地只留临时缓存(用 Git 管版本)。
本地不是不能用,而是只能当同步/备份引擎,不能当协作服务。具体到我自己:需要长期留存或离线兜底的内容,定期导出成 Markdown 用 Git 管版本;而真正的写入、检索、协作,全部发生在 Notion。这两个角色一旦混在一起,前面那三道天花板会立刻找上门。
而真正让这套 Harness 跑起来的,是它把编排的门槛也一并打平了。过去想搭一套像样的 Notion 模板,你得先吃透数据库、属性、视图、关联这一整套概念;想要一个能自动干活的 Agent,门槛更高。现在你只要用大白话把需求说清楚——”帮我建一个稿件库,要有状态、目标渠道、阅读量统计”“再配一个每周帮我汇总流量的助手”——Notion AI 就能把模板搭好、把 Agent 配好。原本属于专家的编排能力,被它压成了一句话的事。
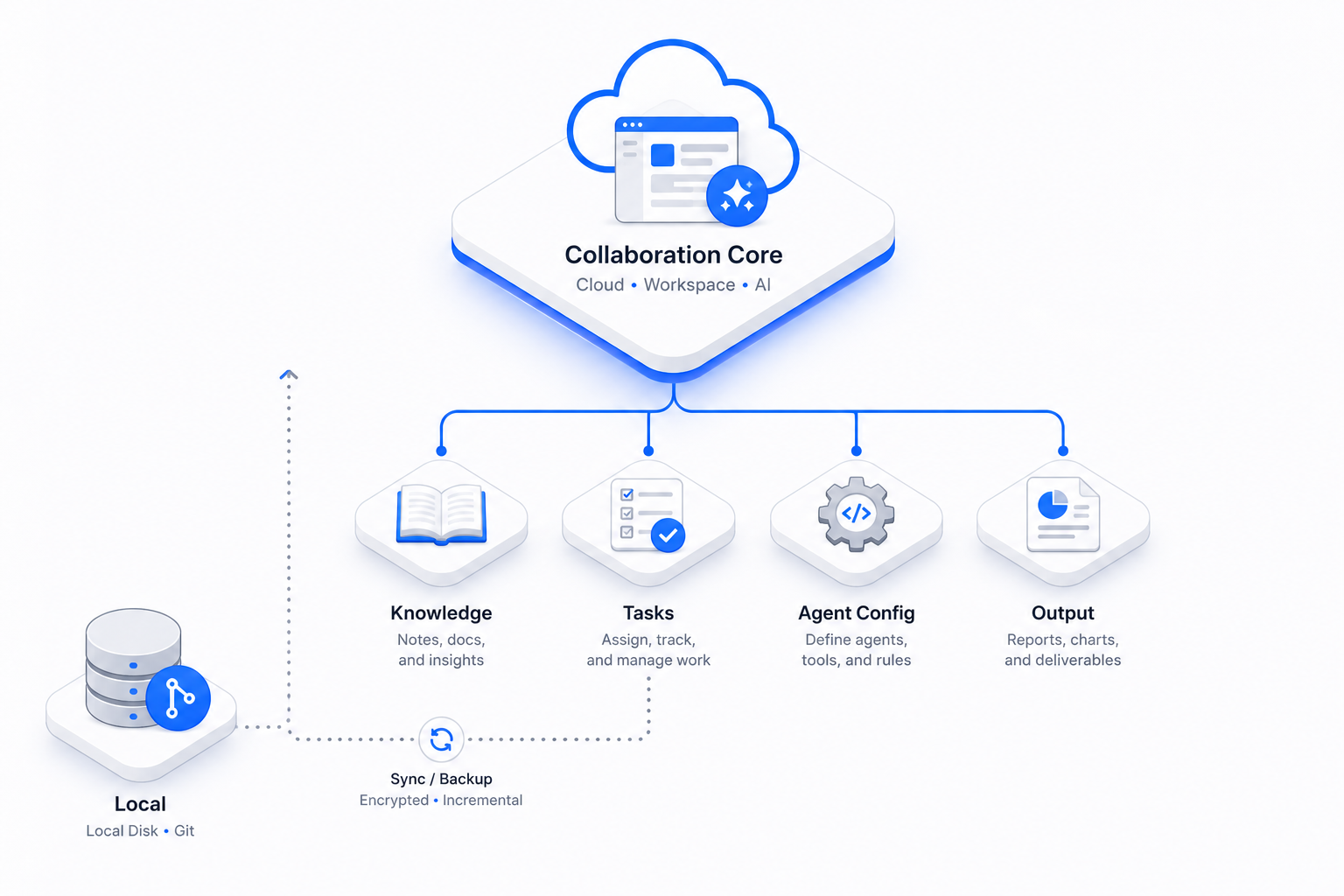
Notion AI 把”模型 × 结构化上下文 × 编排”三件事用极低边际成本打包交付,对一人公司而言,它省下的不是钱,是我最贵的资源——时间与注意力。
结语
“搬回本地”看似是一种潜流,但它真正回应的,是对平台锁定的不安。这份不安是合理的,但解法不是退回单机,而是选一个不锁你、又能把 Harness 打包好的底座。
模型会越来越便宜,这是确定的。不确定的是你能不能把自己的上下文和编排积累成别人拿不走的东西。
而攒这口井,门槛比你想的低得多——你不必先成为数据库或自动化专家,打开 Notion AI,把想法说清楚,剩下的交给它接住。这,才是一人公司真正该押的那口井。
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2026/06/23/从-LLM-Wiki-到-Harness-护城河-一人公司的知识底座为什么是-Notion-AI/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)